# Load Libraries & Data
library(cardinal)
library(dplyr)
adsl <- random.cdisc.data::cadsl
advs <- random.cdisc.data::cadvs
# Pre-Processing - Add any variables needed in your table to df
adsl <- adsl %>%
mutate(AGEGR1 = as.factor(case_when(
AGE >= 17 & AGE < 65 ~ ">=17 to <65",
AGE >= 65 ~ ">=65",
AGE >= 65 & AGE < 75 ~ ">=65 to <75",
AGE >= 75 ~ ">=75"
)))
attr(adsl$AGEGR1, "label") <- "Age Group"
advs <- advs %>%
filter(AVISIT == "BASELINE", VSTESTCD == "TEMP") %>%
select("USUBJID", "AVAL")
anl <- left_join(adsl, advs, by = "USUBJID")
attr(anl$AVAL, "label") <- "Baseline Temperature (C)"
# Output Table
make_table_02(
df = anl,
vars = c("SEX", "AGE", "AGEGR1", "RACE", "ETHNIC", "COUNTRY", "AVAL"),
return_ard = FALSE
)FDA Table 2
Baseline Demographic and Clinical Characteristics, Safety Population, Pooled Analyses
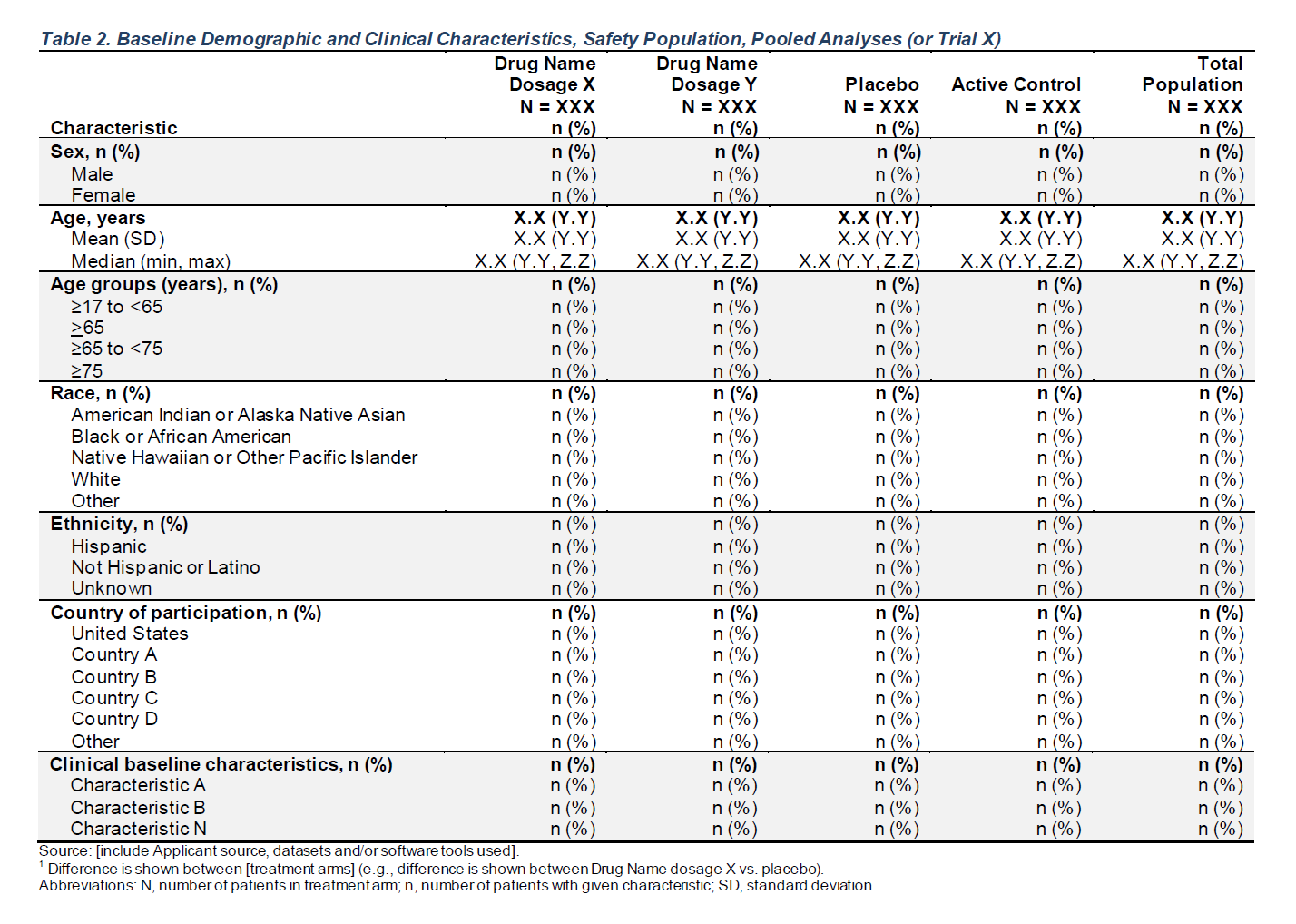
gtsummary Table Setup
| Characteristic |
A: Drug X N = 134 |
B: Placebo N = 134 |
C: Combination N = 132 |
Total Population N = 400 |
|---|---|---|---|---|
| Sex, n (%) | ||||
| F | 79 (59%) | 82 (61%) | 70 (53%) | 231 (58%) |
| M | 55 (41%) | 52 (39%) | 62 (47%) | 169 (42%) |
| Age | ||||
| Mean (SD) | 33.77 (6.55) | 35.43 (7.90) | 35.43 (7.72) | 34.88 (7.44) |
| Median (min - max) | 33.00 (21.00 - 50.00) | 35.00 (21.00 - 62.00) | 35.00 (20.00 - 69.00) | 34.00 (20.00 - 69.00) |
| Age Group, n (%) | ||||
| >=17 to <65 | 134 (100%) | 134 (100%) | 131 (99%) | 399 (100%) |
| >=65 | 0 (0%) | 0 (0%) | 1 (0.8%) | 1 (0.3%) |
| Race, n (%) | ||||
| ASIAN | 68 (51%) | 67 (50%) | 73 (55%) | 208 (52%) |
| BLACK OR AFRICAN AMERICAN | 31 (23%) | 28 (21%) | 32 (24%) | 91 (23%) |
| WHITE | 27 (20%) | 26 (19%) | 21 (16%) | 74 (19%) |
| AMERICAN INDIAN OR ALASKA NATIVE | 8 (6.0%) | 11 (8.2%) | 6 (4.5%) | 25 (6.3%) |
| MULTIPLE | 0 (0%) | 1 (0.7%) | 0 (0%) | 1 (0.3%) |
| NATIVE HAWAIIAN OR OTHER PACIFIC ISLANDER | 0 (0%) | 1 (0.7%) | 0 (0%) | 1 (0.3%) |
| OTHER | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| UNKNOWN | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Ethnicity, n (%) | ||||
| HISPANIC OR LATINO | 15 (11%) | 18 (13%) | 15 (11%) | 48 (12%) |
| NOT HISPANIC OR LATINO | 104 (78%) | 103 (77%) | 101 (77%) | 308 (77%) |
| NOT REPORTED | 6 (4.5%) | 10 (7.5%) | 11 (8.3%) | 27 (6.8%) |
| UNKNOWN | 9 (6.7%) | 3 (2.2%) | 5 (3.8%) | 17 (4.3%) |
| Country, n (%) | ||||
| CHN | 74 (55%) | 81 (60%) | 64 (48%) | 219 (55%) |
| USA | 10 (7.5%) | 13 (9.7%) | 17 (13%) | 40 (10%) |
| BRA | 13 (9.7%) | 7 (5.2%) | 10 (7.6%) | 30 (7.5%) |
| PAK | 12 (9.0%) | 9 (6.7%) | 10 (7.6%) | 31 (7.8%) |
| NGA | 8 (6.0%) | 7 (5.2%) | 11 (8.3%) | 26 (6.5%) |
| RUS | 5 (3.7%) | 8 (6.0%) | 6 (4.5%) | 19 (4.8%) |
| JPN | 5 (3.7%) | 4 (3.0%) | 9 (6.8%) | 18 (4.5%) |
| GBR | 4 (3.0%) | 3 (2.2%) | 2 (1.5%) | 9 (2.3%) |
| CAN | 3 (2.2%) | 2 (1.5%) | 3 (2.3%) | 8 (2.0%) |
| CHE | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Baseline Temperature (C) | ||||
| Mean (SD) | 36.66 (1.02) | 36.63 (1.07) | 36.48 (1.00) | 36.59 (1.03) |
| Median (min - max) | 36.67 (33.97 - 39.28) | 36.63 (33.59 - 38.92) | 36.49 (34.21 - 38.95) | 36.60 (33.59 - 39.28) |
Function Details
make_table_02()
Required variables:
-
df: The variables specified byvars,arm_var, andsaffl_var. -
denominator(if specified):USUBJIDand the variables specified byarm_varandsaffl_var.
| Argument | Description | Default |
df |
(data.frame) Dataset (typically ADSL) required to build table. |
No default |
return_ard |
(flag) Whether an ARD should be returned. |
TRUE |
arm_var |
(character) Arm variable used to split table into columns. |
"ARM" |
saffl_var |
(character) Flag variable used to indicate inclusion in safety population. |
"SAFFL" |
id_var |
(character) Identifier variable used to count the participants within each flag. |
"USUBJID" |
Source code for this function is available here.
ARD Setup
# Load Libraries & Data
library(cardinal)
library(dplyr)
adsl <- random.cdisc.data::cadsl
advs <- random.cdisc.data::cadvs
# Pre-Processing - Add any variables needed in your table to df
adsl <- adsl %>%
mutate(AGEGR1 = as.factor(case_when(
AGE >= 17 & AGE < 65 ~ ">=17 to <65",
AGE >= 65 ~ ">=65",
AGE >= 65 & AGE < 75 ~ ">=65 to <75",
AGE >= 75 ~ ">=75"
)))
advs <- advs %>%
filter(AVISIT == "BASELINE", VSTESTCD == "TEMP") %>%
select("USUBJID", "AVAL")
anl <- left_join(adsl, advs, by = "USUBJID")
attr(anl$AVAL, "label") <- "Baseline Temperature (C)"
# Create Table & ARD
result <- make_table_02(
df = anl,
vars = c("SEX", "AGE", "AGEGR1", "RACE", "ETHNIC", "COUNTRY", "AVAL")
)
# Output ARD
result$ard$tbl_summary{cards} data frame: 401 x 12 group1 group1_level variable variable_level context stat_name stat_label stat fmt_fn warning error gts_column
1 ARM A: Drug X SEX F categori… n n 79 <fn> stat_1
2 ARM A: Drug X SEX F categori… N N 134 <fn> stat_1
3 ARM A: Drug X SEX F categori… p % 0.59 <fn> stat_1
4 ARM A: Drug X SEX M categori… n n 55 <fn> stat_1
5 ARM A: Drug X SEX M categori… N N 134 <fn> stat_1
6 ARM A: Drug X SEX M categori… p % 0.41 <fn> stat_1
7 ARM A: Drug X AGEGR1 >=17 to … categori… n n 134 <fn> stat_1
8 ARM A: Drug X AGEGR1 >=17 to … categori… N N 134 <fn> stat_1
9 ARM A: Drug X AGEGR1 >=17 to … categori… p % 1 <fn> stat_1
10 ARM A: Drug X AGEGR1 >=65 categori… n n 0 <fn> stat_1ℹ 391 more rowsℹ Use `print(n = ...)` to see more rows
$add_overall{cards} data frame: 143 x 10 variable variable_level context stat_name stat_label stat fmt_fn warning error gts_column
1 SEX F categori… n n 231 <fn> stat_0
2 SEX F categori… N N 400 <fn> stat_0
3 SEX F categori… p % 0.578 <fn> stat_0
4 SEX M categori… n n 169 <fn> stat_0
5 SEX M categori… N N 400 <fn> stat_0
6 SEX M categori… p % 0.423 <fn> stat_0
7 AGEGR1 >=17 to … categori… n n 399 <fn> stat_0
8 AGEGR1 >=17 to … categori… N N 400 <fn> stat_0
9 AGEGR1 >=17 to … categori… p % 0.998 <fn> stat_0
10 AGEGR1 >=65 categori… n n 1 <fn> stat_0ℹ 133 more rows
ℹ Use `print(n = ...)` to see more rowsrtables Table Setup
# Load Libraries & Data
# Load Libraries & Data
library(cardinal)
library(dplyr)
adsl <- random.cdisc.data::cadsl
advs <- random.cdisc.data::cadvs
# Pre-Processing - Add any variables needed in your table to df
adsl <- adsl %>%
mutate(AGEGR1 = as.factor(case_when(
AGE >= 17 & AGE < 65 ~ ">=17 to <65",
AGE >= 65 ~ ">=65",
AGE >= 65 & AGE < 75 ~ ">=65 to <75",
AGE >= 75 ~ ">=75"
)))
advs <- advs %>%
filter(AVISIT == "BASELINE", VSTESTCD == "TEMP") %>%
select("USUBJID", "AVAL")
anl <- left_join(adsl, advs, by = "USUBJID")
# Output Table
make_table_02_rtables(
df = anl,
vars = c("SEX", "AGE", "AGEGR1", "RACE", "ETHNIC", "COUNTRY", "AVAL"),
lbl_vars = c(
"Sex", "Age, years", "Age Group, years", "Race", "Ethnicity",
"Country of Participation", "Baseline Temperature (C)"
)
) A: Drug X B: Placebo C: Combination Total Population
Characteristic (N=134) (N=134) (N=132) (N=400)
———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
Sex
F 79 (59%) 82 (61.2%) 70 (53%) 231 (57.8%)
M 55 (41%) 52 (38.8%) 62 (47%) 169 (42.2%)
Age, years
Mean (SD) 33.8 (6.6) 35.4 (7.9) 35.4 (7.7) 34.9 (7.4)
Median (Min - Max) 33.0 (21.0 - 50.0) 35.0 (21.0 - 62.0) 35.0 (20.0 - 69.0) 34.0 (20.0 - 69.0)
Age Group, years
>=17 to <65 134 (100%) 134 (100%) 131 (99.2%) 399 (99.8%)
>=65 0 0 1 (0.8%) 1 (0.2%)
Race
ASIAN 68 (50.7%) 67 (50%) 73 (55.3%) 208 (52%)
BLACK OR AFRICAN AMERICAN 31 (23.1%) 28 (20.9%) 32 (24.2%) 91 (22.8%)
WHITE 27 (20.1%) 26 (19.4%) 21 (15.9%) 74 (18.5%)
AMERICAN INDIAN OR ALASKA NATIVE 8 (6%) 11 (8.2%) 6 (4.5%) 25 (6.2%)
MULTIPLE 0 1 (0.7%) 0 1 (0.2%)
NATIVE HAWAIIAN OR OTHER PACIFIC ISLANDER 0 1 (0.7%) 0 1 (0.2%)
Ethnicity
HISPANIC OR LATINO 15 (11.2%) 18 (13.4%) 15 (11.4%) 48 (12%)
NOT HISPANIC OR LATINO 104 (77.6%) 103 (76.9%) 101 (76.5%) 308 (77%)
NOT REPORTED 6 (4.5%) 10 (7.5%) 11 (8.3%) 27 (6.8%)
UNKNOWN 9 (6.7%) 3 (2.2%) 5 (3.8%) 17 (4.2%)
Country of Participation
CHN 74 (55.2%) 81 (60.4%) 64 (48.5%) 219 (54.8%)
USA 10 (7.5%) 13 (9.7%) 17 (12.9%) 40 (10%)
BRA 13 (9.7%) 7 (5.2%) 10 (7.6%) 30 (7.5%)
PAK 12 (9%) 9 (6.7%) 10 (7.6%) 31 (7.8%)
NGA 8 (6%) 7 (5.2%) 11 (8.3%) 26 (6.5%)
RUS 5 (3.7%) 8 (6%) 6 (4.5%) 19 (4.8%)
JPN 5 (3.7%) 4 (3%) 9 (6.8%) 18 (4.5%)
GBR 4 (3%) 3 (2.2%) 2 (1.5%) 9 (2.2%)
CAN 3 (2.2%) 2 (1.5%) 3 (2.3%) 8 (2%)
Baseline Temperature (C)
Mean (SD) 36.7 (1.0) 36.6 (1.1) 36.5 (1.0) 36.6 (1.0)
Median (Min - Max) 36.7 (34.0 - 39.3) 36.6 (33.6 - 38.9) 36.5 (34.2 - 38.9) 36.6 (33.6 - 39.3)Function Details
make_table_02_rtables()
Required variables:
-
df: The variables specified byvars,arm_var, andsaffl_var. -
alt_counts_df(if specified):USUBJIDand the variables specified byarm_varandsaffl_var.
| Argument | Description | Default |
|---|---|---|
df |
(data.frame) Dataset (typically ADSL) required to build table. |
No default |
show_colcounts |
(flag) Whether column counts should be printed. |
TRUE |
arm_var |
(character) Arm variable used to split table into columns. |
"ARM" |
saffl_var |
(character) Flag variable used to indicate inclusion in safety population. |
"SAFFL" |
vars |
(character) Variables from df to include in the table. |
c("SEX", "AGE", "AGEGR1", "RACE", "ETHNIC", "COUNTRY") |
lbl_vars |
(character) Labels corresponding to variables in vars to print in the table. Labels should be ordered according to the order of variables in vars. |
formatters::var_labels(df, fill = TRUE)[vars] |
lbl_overall |
(character) If specified, an overall column will be added to the table with the given value as the column label. |
"Total Population" |
prune_0 |
(flag) Whether all-zero rows should be removed from the table. |
TRUE |
na_rm |
(flag) Whether NA levels should be removed from the table. |
FALSE |
annotations |
(named list of character) List of annotations to add to the table. Valid annotation types are title, subtitles, main_footer, and prov_footer. Each name-value pair should use the annotation type as name and the desired string as value. |
NULL |
Source code for this function is available here.